Hey folks,
Last week we covered Transformers - the architecture behind ChatGPT, Claude, and modern AI.
Throughout that issue (and Issues #44, #45), I kept mentioning "embeddings" without really explaining what they are. Time to fix that.
Computers Don't Understand Words
Computers work with numbers. They can add, multiply, compare. But they can't read.
When you type "cat" into ChatGPT, the model doesn't see the word "cat." It sees numbers. So we need a way to turn words into numbers.
The Old Way: One-Hot Encoding
The simplest approach is to give each word a unique ID.
Imagine a vocabulary of 4 words: cat, dog, bird, car.
cat = [1, 0, 0, 0]
dog = [0, 1, 0, 0]
bird = [0, 0, 1, 0]
car = [0, 0, 0, 1]
Each word gets a vector with a single "1" in its position. Everything else is zero.
This works. But there's a problem.
Look at "cat" and "dog." Both are animals. Related concepts. But their vectors are completely different. No similarity at all.
And "cat" and "car"? Totally unrelated. But to the computer, they look just as different as cat and dog.
One-hot encoding treats every word as equally different from every other word. It captures no meaning.
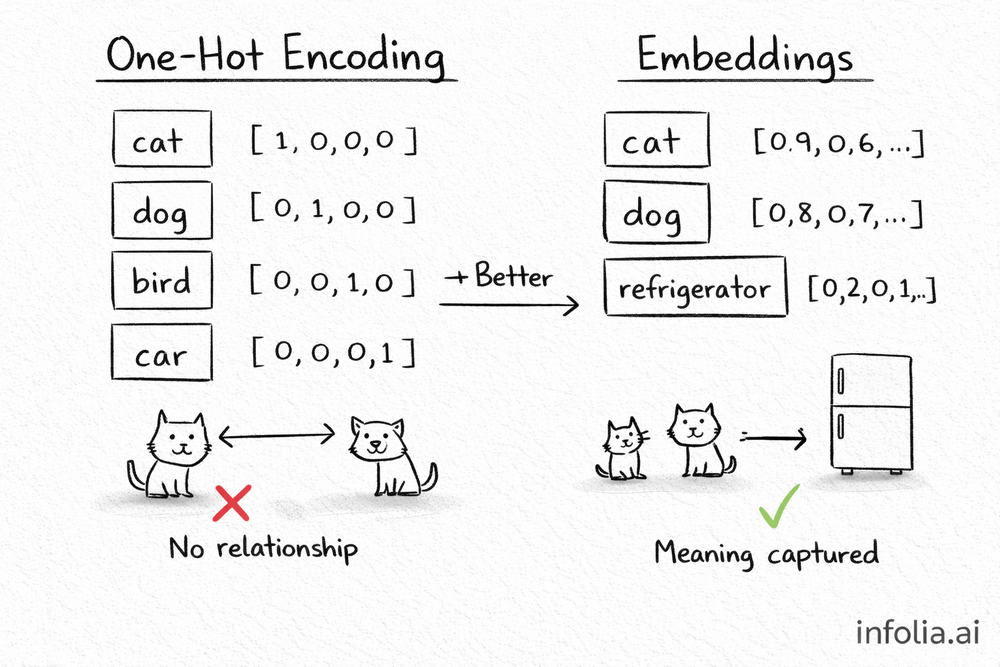
The Better Way: Embeddings
What if we placed words in a space where similar meanings are close together?
Instead of [1, 0, 0, 0], the word "cat" becomes something like:
cat = [0.2, 0.8, 0.1, 0.5, 0.3, ...]
A list of numbers. Typically 256 to 1536 of them. These numbers don't mean anything individually. But together, they capture the essence of what "cat" means.
And "dog" has similar numbers:
cat = [0.2, 0.8, 0.1, 0.5, 0.3, ...]
dog = [0.3, 0.7, 0.2, 0.5, 0.4, ...]
Close values. Because cats and dogs are semantically similar. Both pets, both animals.
Meanwhile "refrigerator" looks completely different:
refrigerator = [0.9, 0.1, 0.8, 0.2, 0.7, ...]
Far away in the number space. Because refrigerators have nothing to do with cats.
Words as Points in Space
Think of it visually.
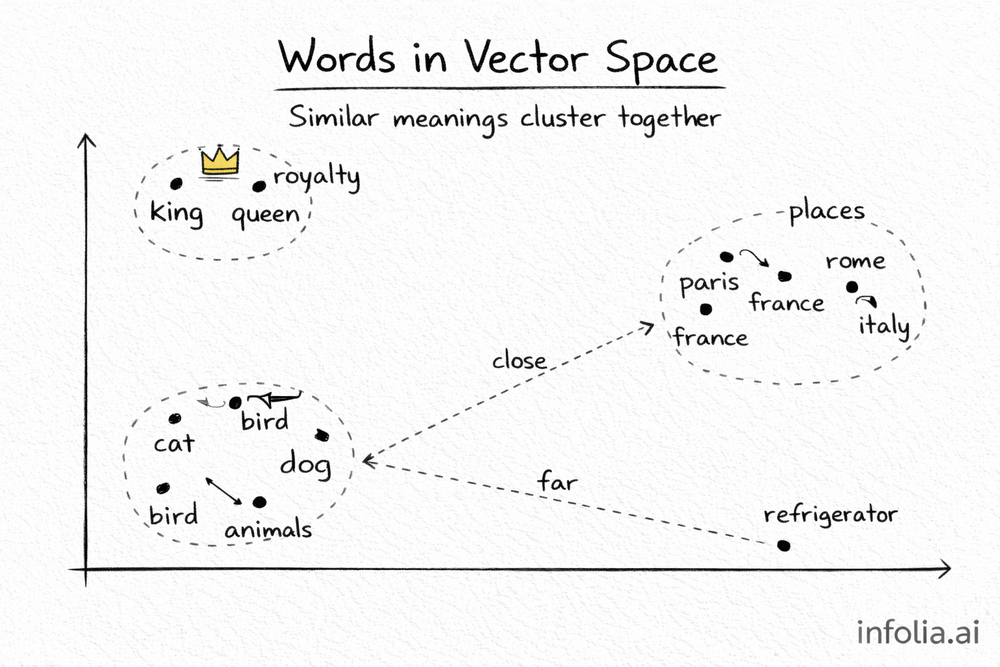
Imagine a 3D space. Each word is a point in that space. "Cat" and "dog" are close together. "King" and "queen" are close together. "Paris" and "France" are close together.
"Cat" and "democracy"? Far apart.
This is what "vector space" means. Words become vectors (lists of numbers), and similar words cluster together. Real embeddings have hundreds of dimensions, not just 3. But the idea is the same.
King - Man + Woman = Queen
This is my favorite example.
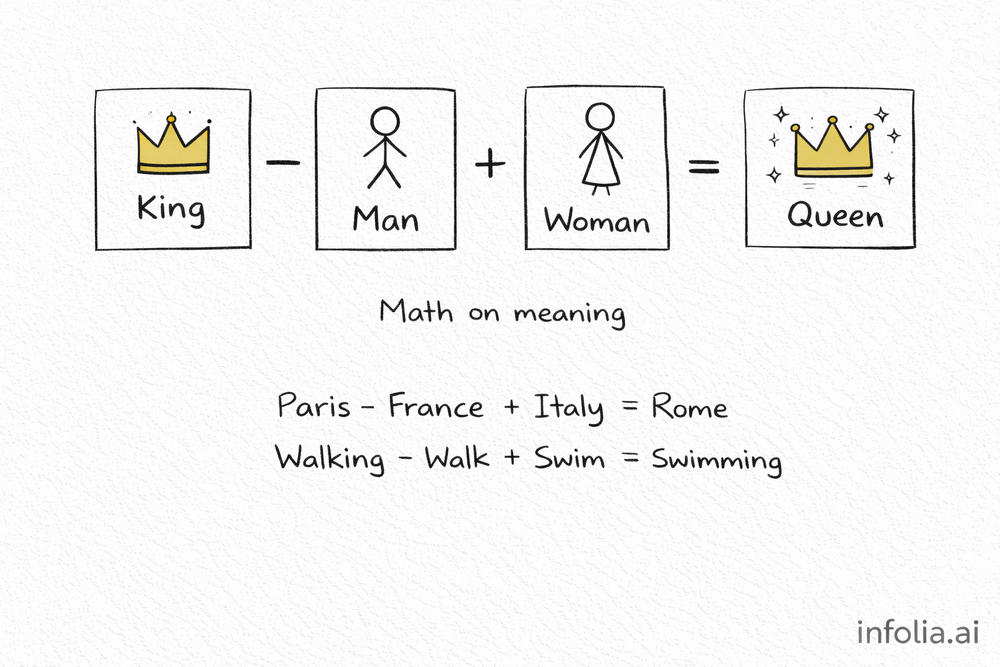
Take the embedding for "king." Subtract the embedding for "man." Add the embedding for "woman."
What do you get? A vector very close to "queen."
king - man + woman ≈ queen
The embeddings captured that "king" is to "man" what "queen" is to "woman." The relationship is encoded in the numbers.
Other examples that work:
- Paris - France + Italy ≈ Rome
- Walking - Walk + Swim ≈ Swimming
You can do math on meaning. That still blows my mind.
How Are Embeddings Created?
You don't hand-code these numbers. They're learned.
The basic idea: train a model on tons of text. The model learns to predict words from context. As it learns, it develops internal representations for each word. Those representations become the embeddings.
Models like Word2Vec and GloVe started this approach. Modern transformer-based models take it further. OpenAI's text-embedding-ada-002, Cohere's embed models - they're trained on billions of words. Their embeddings are remarkably good at capturing meaning.
You've Already Seen Embeddings
Remember the previous issues?
In Issue #46 (Transformers), I showed positional encoding being added to word embeddings:
"cat" embedding: [0.3, 0.5, 0.2, ...]
Position 2 encoding: [0.1, -0.2, 0.4, ...]
Final input: [0.4, 0.3, 0.6, ...]
That "cat embedding" - now you know what it actually is. A learned vector capturing what "cat" means.
In Issue #44 (Attention), the Query-Key-Value mechanism compares and combines embeddings. In Issue #43 (RNNs), the hidden state is an embedding of the sequence so far.
Embeddings are everywhere in neural networks.
Where Embeddings Show Up in Real Products
When you search "how to fix a bug" and Google returns results about "debugging tips" - that's embeddings. Your query gets embedded. Documents get embedded. The search engine finds documents with similar embeddings to your query. The words don't need to match. The meaning matches.
Netflix recommendations work similarly. Movies get embedded. Your watch history gets embedded. Similar embeddings surface similar content.
RAG (Retrieval-Augmented Generation) uses embeddings too. This is how ChatGPT plugins and custom knowledge bases work. Embed your documents. When a question comes in, find chunks with similar embeddings. Feed those to the LLM. We'll cover RAG properly next.
Key Takeaway
Embeddings turn meaning into math.
Words become vectors. Similar meanings cluster together. Different meanings stay far apart. And you can do arithmetic on these vectors - that's how "King - Man + Woman = Queen" works.
This is how AI "understands" language. Not by reading words, but by operating on learned vectors that represent meaning.
What's Next
Next week, we start Phase 3: Practical AI Concepts. First up: RAG (Retrieval-Augmented Generation).
Test your knowledge → Take the quiz
Read the full AI Learning series → Learn AI
New here? Subscribe → infolia.ai/subscribe
How was today's email?
