In January 2026, DeepSeek R1 became the #1 app on the App Store in dozens of countries overnight. The Chinese startup had trained a frontier-level reasoning model for $6 million, while OpenAI and Anthropic were spending $100 million to $1 billion on comparable models.
The AI community erupted with predictions about the death of closed models. Open source had finally caught up, or so the story went.
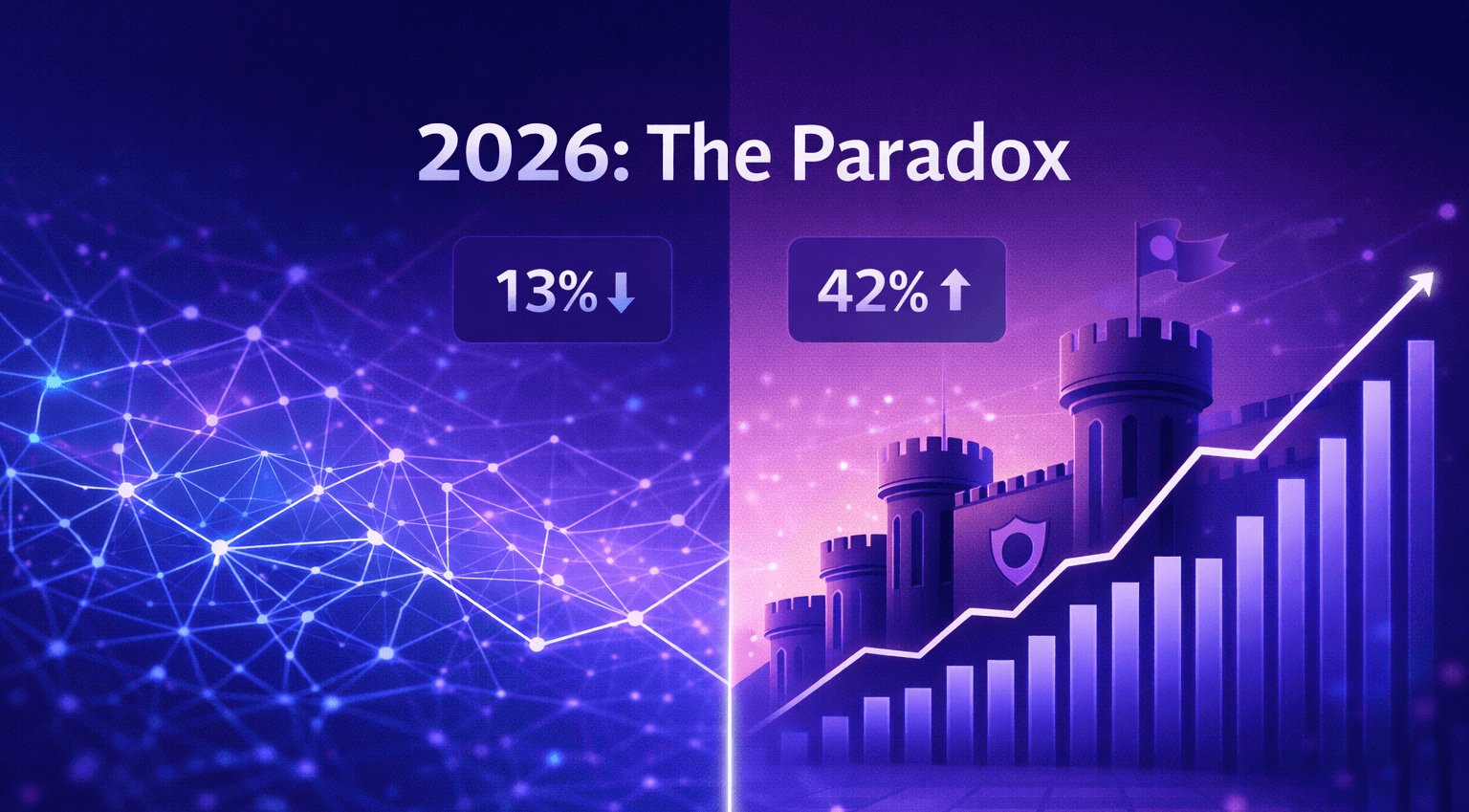
But the data tells a different story. Open source's market share actually dropped from 19% to 13% over the last six months. This paradox (spectacular technical achievements alongside declining adoption) reveals what's really happening in the LLM landscape.
The Current Landscape
The open source ecosystem has matured significantly. Meta's Llama remains the market leader, with models ranging from 7B to 405B parameters. DeepSeek V3.2 pushes the envelope at 685 billion parameters with a 128K context window. OpenAI released GPT-OSS, their first open weights since GPT-2 in 2019. Mistral, Qwen, and Gemma each serve specific niches.
The models themselves are impressive. But adoption numbers reveal a disconnect between capability and deployment. Gartner forecast that 60%+ of enterprises would adopt open-source LLMs by 2025. The reality: only 13% of AI workloads currently run on open source models, down from 19% six months earlier.
The drop coincides with Anthropic's Claude capturing 42% of the code generation market, more than double OpenAI's 21%. Developers chose reliability over cost savings.
Geographic adoption splits along predictable lines. DeepSeek dominates China (89% market share), Russia (43%), and developing markets. Western enterprises stick with domestic vendors, citing security concerns and compliance requirements. Llama maintains the strongest global footprint among open source options.
Deloitte's research shows open source LLMs deliver 40% cost savings while achieving comparable performance to proprietary alternatives. If that's true, the adoption gap demands explanation.
Cost Economics: API vs Self-Hosting
The "open source equals free" assumption breaks down quickly under scrutiny. While model weights are freely available, deployment costs tell a more complex story.
API Pricing
Open source models accessible via API providers offer compelling economics:
| Model | Cost per 1M tokens |
|---|---|
| Llama 3.3 70B (DeepInfra) | $0.12 |
| Gemini Flash | $0.075 / $0.30 |
| GPT-4 | $30 / $60 |
Llama 70B via API costs 30x less than GPT-4 while delivering equivalent factual accuracy on tasks like summarization. This pricing advantage holds across most open source models when accessed through optimized API providers.
Self-Hosting Economics
Infrastructure requirements for self-hosted deployments change the cost equation substantially.
Entry-level setups for 7B-13B models require $600-$3,000 monthly in GPU costs. A single H100 GPU running continuously costs approximately $1,500 per month. Engineering overhead (infrastructure management, monitoring, security) typically accounts for 70-80% of total deployment costs.
Mid-tier deployments for models like Llama 70B run $15,000-$40,000 monthly. These require 4-8 GPUs with high-speed interconnects, robust networking infrastructure, and dedicated operations personnel.
A real-world comparison: one startup spent $1,200 running tests on Llama 2. Identical tests on GPT-3.5 Turbo cost $5.
The break-even threshold sits around 2 million tokens daily. Below that volume, API economics dominate. Above it, self-hosting can deliver cost advantages, but only with sufficient technical capability to manage the infrastructure efficiently. Payback periods typically run 6-12 months for teams with appropriate volume and expertise.
Comparing the same 1 million token workload across deployment methods:
- DeepInfra API: $0.12
- Lambda Labs self-hosting: $43
- Azure self-hosting: $88
For most organizations, API costs run 50-700x lower than self-hosting infrastructure when accounting for all operational expenses.
Performance Analysis
Open source models demonstrate competitive performance on specific benchmarks while showing gaps in others.
Competitive Areas
On well-defined tasks, open source models match or exceed closed alternatives. Llama 2 70B achieves 85% factual accuracy on summarization, matching GPT-4's performance. DeepSeek scores 98/100 on coding benchmarks versus OpenAI's 97, and hits 97/100 on mathematical reasoning compared to OpenAI's 95.
Llama 3 70B delivers up to 10x faster response times than GPT-4 when accessed through optimized API providers, though this advantage varies significantly based on infrastructure and implementation.
Performance Gaps
DeepSeek's technical documentation acknowledges remaining limitations: "Breadth of world knowledge still lags behind leading proprietary models," "Token efficiency remains a challenge," and "Solving complex tasks is still inferior to frontier models."
These limitations manifest most clearly in production environments. Open source models excel at specific, repeatable tasks but struggle with edge cases, nuanced interpretation, and open-ended problem-solving.
Meta's Llama 4 launch in April 2025 illustrates the gap between benchmarks and real-world performance. Despite strong technical specifications, Menlo Ventures characterized its production performance as "underwhelming in real-world settings."
This performance-reliability gap explains why enterprises accept 30x higher costs for Claude and GPT-4 in mission-critical applications. Benchmarks measure capability. Production measures dependability.
Deployment Decision Framework
Self-hosted open source deployments make sense under specific conditions: daily volume exceeding 2 million tokens, technical teams capable of managing ML operations, strict compliance requirements (HIPAA, GDPR), need for extensive customization through fine-tuning, or handling of highly sensitive data in healthcare, finance, or legal contexts.
A telemedicine company reduced monthly AI costs from $48,000 to $32,000 by self-hosting a fine-tuned model for patient chat triage. The company needed HIPAA compliance and processed sufficient volume to justify infrastructure investment.
Closed API services remain appropriate for smaller teams (under 10 people), prototyping and initial development, low-to-medium volume workloads, applications requiring cutting-edge capabilities, and organizations prioritizing simplicity over infrastructure control.
Hybrid Architecture
Most production systems don't choose exclusively between open source and closed models. Successful deployments route different request types to different models based on complexity and requirements.
Simple queries flow to smaller, faster models like Llama 7B. Medium-complexity tasks use Llama 70B via API. Complex reasoning requirements route to Claude or GPT-4. Batch processing jobs run on self-hosted infrastructure while real-time user-facing requests use API services.
Organizations implementing hybrid approaches report 40% cost savings while maintaining output quality, according to Deloitte's analysis.
The DeepSeek Factor
DeepSeek's January 2026 launch demonstrated that efficient training methods can deliver frontier-model performance at $6 million, orders of magnitude below the $100 million-plus budgets of GPT-4 and Claude. The model matches GPT-5 on reasoning benchmarks, carries an MIT license with no usage restrictions, and achieved viral adoption by becoming the #1 app on the App Store in multiple countries overnight.
Despite these technical achievements, Western enterprise adoption remains limited. Data storage on Chinese servers raises privacy concerns. China's national intelligence law Article 7 requires organizations to cooperate with intelligence requests. The model refuses to answer questions on politically sensitive topics. Attempting to query about the 1989 Tiananmen Square protests returns: "Sorry, I'm not sure how to approach this type of question yet." Microsoft and other major Western technology companies have restricted internal use.
DeepSeek's primary impact extends beyond direct adoption numbers. The launch proved that frontier-model training doesn't require massive compute budgets. OpenAI responded by releasing GPT-OSS, their first open weights since GPT-2 in 2019. The announcement accelerated pricing competition across the industry. Sam Altman acknowledged: "We may be underestimating China's AI progress."
Everest Group analyst Oishi Mazumder summarized the strategic shift: "DeepSeek accelerates commoditization of raw AI capability, eroding the closed-model moat."
Yet commoditization hasn't translated to market share gains. The 13% adoption figure persists.
Market Impact Assessment
Open source LLMs have not displaced closed models in production deployments. Market share decreased from 19% to 13% while Claude captured 42% of code generation workloads. Enterprise priorities favor reliability over cost optimization.
The actual disruption manifested differently than predicted. Pricing pressure forced proprietary providers to compete more aggressively. GPT-4 Turbo costs one-third the price of the original GPT-4. Open source models dominate specific niches: fine-tuning for specialized domains, compliance-constrained environments, and high-volume batch processing. DeepSeek's efficiency breakthrough compelled OpenAI to release open weights for the first time in six years. Most significantly, hybrid architectures emerged as the dominant production pattern rather than exclusive commitment to either approach.
Open source availability democratized access to frontier-model capabilities for organizations unable to fund $100 million training runs. Competitive pressure improved both pricing and quality across proprietary offerings. A substantial middle market developed between hobbyist experimentation and enterprise-scale closed deployments.
For development teams evaluating options in 2026: API access to models like Llama through OpenRouter costs $0.12 per million tokens, appropriate for initial deployment and volume assessment. Self-hosting makes economic sense only with sustained volume exceeding 2 million tokens daily plus technical capacity for infrastructure management. DeepSeek warrants attention for its technical innovations while requiring careful evaluation of data privacy and content restrictions. Hybrid architectures should be the default consideration rather than an afterthought.
The industry will likely see continued development of industry-specific model variants for healthcare, legal, and financial applications. Pricing competition will intensify as open source maintains pressure on proprietary providers. Infrastructure tooling for self-hosting will mature substantially. Hybrid architectures will become increasingly sophisticated in their routing logic and model selection.
Open source models didn't eliminate the need for closed alternatives. They created a more competitive, accessible AI ecosystem. That outcome may prove more valuable than outright market dominance.
Understanding model architecture (transformers, embeddings, attention mechanisms) provides essential context for evaluating these deployment options. I cover these fundamentals in the Infolia AI tutorial series, designed specifically for developers implementing AI systems.