Hey folks,
Last week we covered Convolutional Neural Networks - how neural networks process spatial data like images through sliding filters and hierarchical features.
This week: How neural networks process sequential data.
CNNs excel at images where spatial relationships matter. For sequences where temporal order matters—text, speech, time series—we need a different architecture: Recurrent Neural Networks.
Let's break it down.
The Problem with Fixed-Size Inputs
CNNs and fully-connected networks expect fixed-size inputs. A 224×224×3 image always has the same dimensions.
But sequences vary wildly in length:
- "Hi" = 1 word
- "Hello, how are you doing today?" = 6 words
- "The quick brown fox jumps over the lazy dog" = 9 words
More importantly, order determines meaning. "Dog bites man" means something completely different from "Man bites dog." Standard neural networks treat inputs as unordered features, which breaks for sequences.
What Makes Data Sequential
Sequential data has temporal dependencies—the current element depends on previous ones.
Text: To predict "The cat sat on the ___", you need context. Without knowing there's a "cat," you can't confidently predict "mat."
Speech: Phonemes combine into words over time. "Recognize speech" sounds identical to "wreck a nice beach" until you process the full temporal pattern.
Time series: Today's stock price is influenced by yesterday's. Tomorrow's weather depends on today's conditions. Current sensor readings predict future values.
The pattern: order matters, and past influences future.
Recurrent Connections: How RNNs Remember
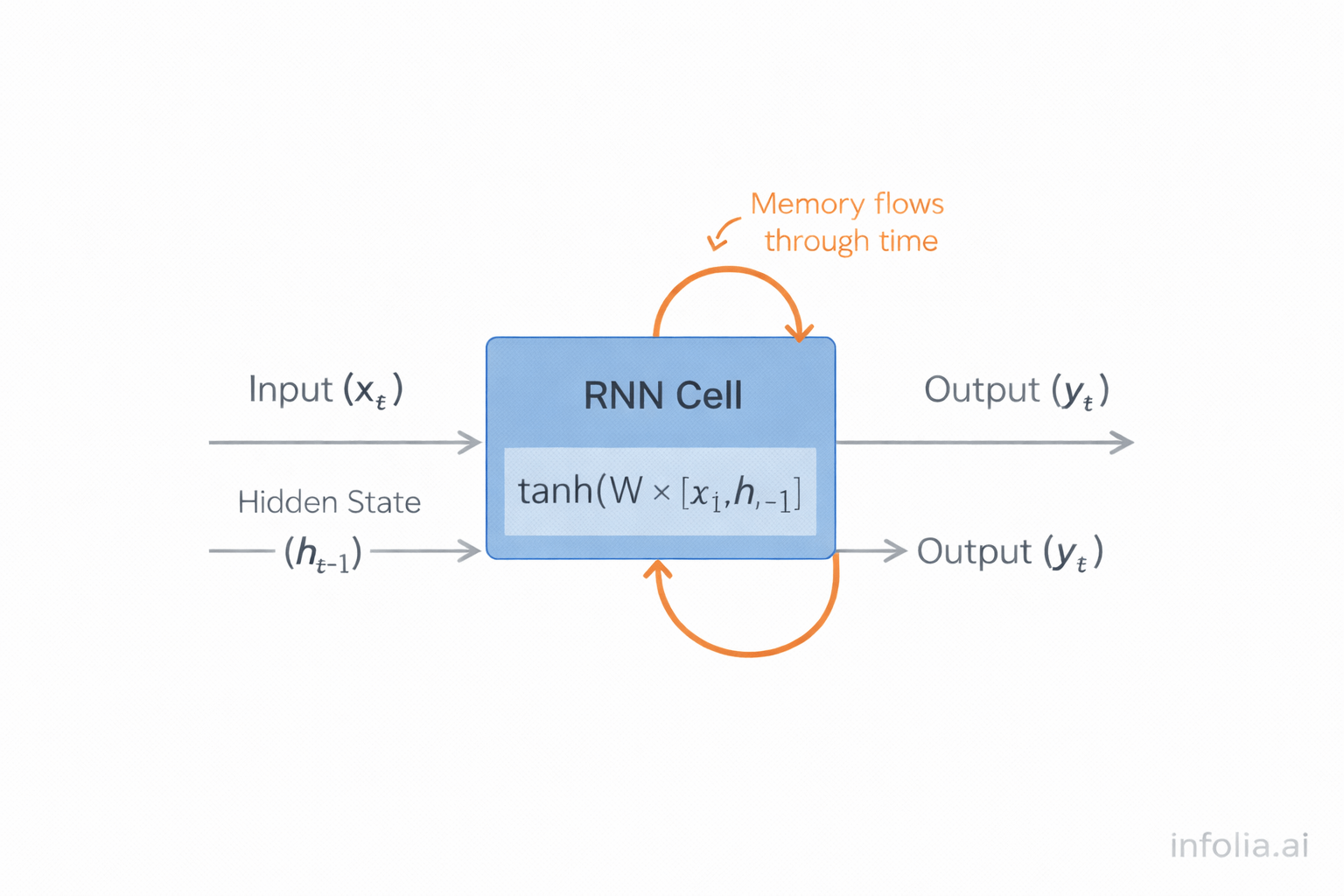
RNNs solve the sequence problem by introducing hidden state that persists across time steps.
At each step, an RNN cell receives two inputs: the current token and the hidden state from the previous step. It updates the hidden state and produces an output.
hidden_new = tanh(W × [input, hidden_old])
output = V × hidden_new
The hidden state acts as memory, carrying information forward through time. This loop structure—where hidden state feeds back into itself—enables the network to maintain context.
The Unrolled View
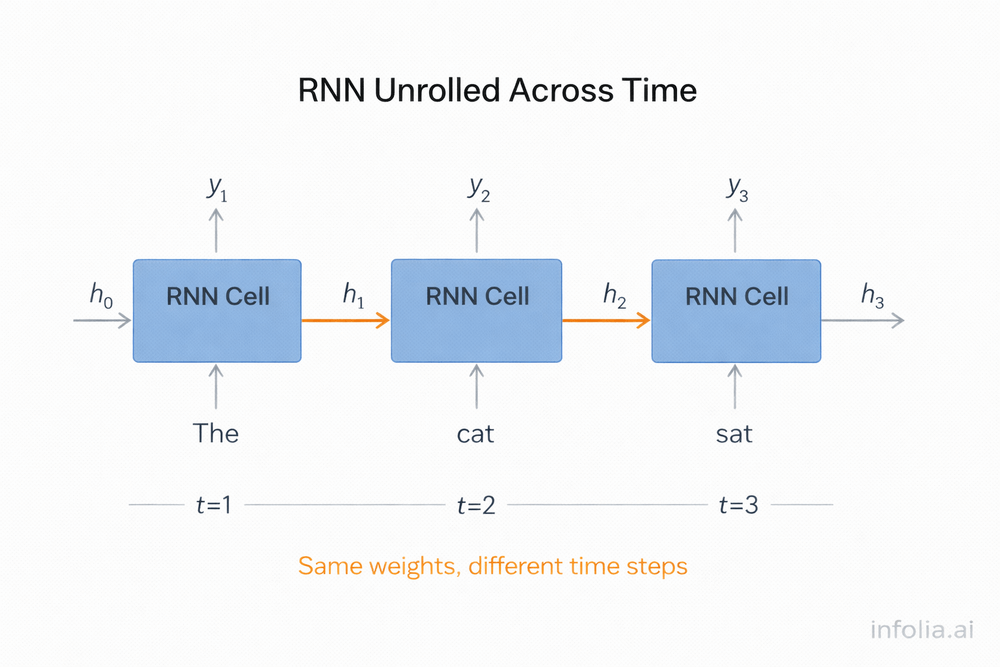
RNNs are easier to understand when "unrolled" across time. Processing "The cat sat" looks like this:
Step 1: Process "The" with an initialized hidden state. Update the state to reflect "The."
Step 2: Process "cat" with the hidden state containing "The." Now the state represents "The cat."
Step 3: Process "sat" with the hidden state containing "The cat." Make a prediction with full context.
The same RNN cell processes each word. The hidden state accumulates context as the sequence progresses. This is parameter sharing across time, similar to how CNNs share filters across space.
Vanishing Gradient Problem
Basic RNNs struggle with long sequences because information from early steps fades away.
During backpropagation, gradients flow backward through time. At each step, they're multiplied by weights. After many steps, these repeated multiplications cause gradients to shrink exponentially toward zero.
Consider: "The cat that my friend from college adopted last year sat on the mat."
By the time the network reaches "sat," the gradient signal from "cat" has vanished. The network can't learn the long-range dependency between subject and verb.
Basic RNNs work for sequences of 10-20 steps. Beyond that, early information disappears.
LSTM: Long Short-Term Memory
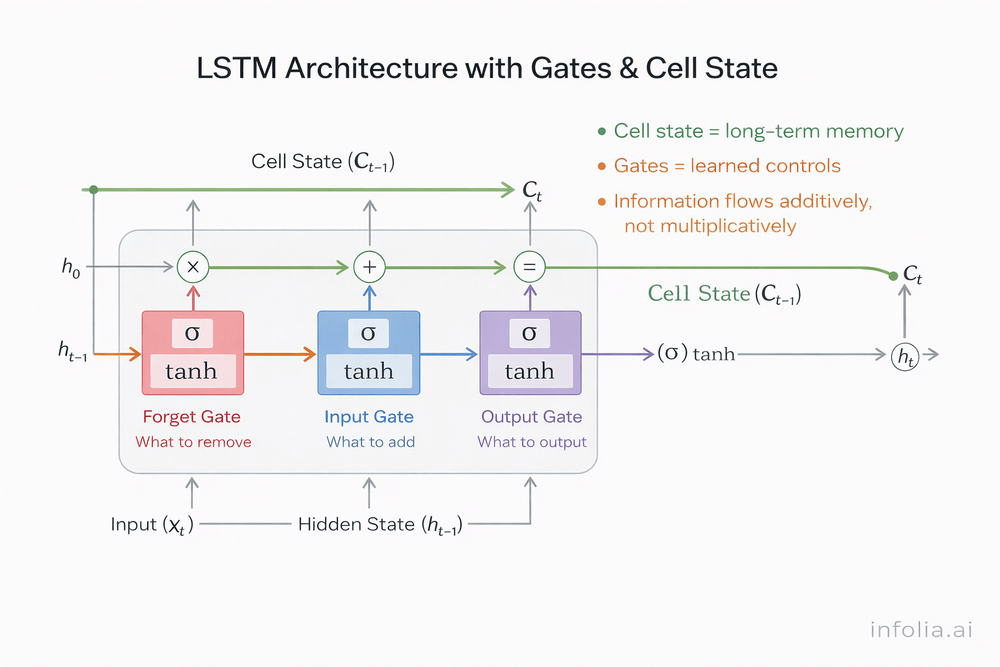
LSTMs solve vanishing gradients through gating mechanisms that control information flow.
The innovation: maintaining two types of state. The cell state acts as long-term memory, flowing through time with minimal modification. The hidden state handles immediate computations and shorter-term context.
Three gates regulate what information enters, leaves, or persists in the cell state:
Forget gate: Decides what to discard from cell state. When starting a new sentence, forget the previous sentence's subject.
Input gate: Decides what new information to store. When seeing "The cat," store "cat" as the subject for future reference.
Output gate: Decides what from cell state to output at this step. When predicting the next word, select relevant memorized information.
Why does this work? The cell state provides a highway for gradients. Information flows through 100+ time steps without vanishing because gates add or remove information instead of multiplying it repeatedly.
LSTMs handle sequences of 100-200 steps effectively, enabling machine translation and long document analysis.
GRU: Gated Recurrent Unit
GRUs simplify LSTMs while maintaining similar performance. Instead of three gates, GRUs use two: a reset gate (how much past to forget) and an update gate (how much new information to add). There's no separate cell state—everything combines into one hidden state.
The advantage: fewer parameters mean faster training. GRUs work well for moderately long sequences (50-100 steps). The choice between LSTM and GRU is often empirical—try both and see which performs better.
Applications
Text generation: Given "The quick brown," predict "fox." The RNN processes each word, updating hidden state. The final state feeds a prediction layer that outputs "fox." Continue generating: "jumps," "over," "the." This powers autocomplete and chatbots.
Machine translation: An encoder RNN processes "The cat sat on the mat" in English. Its final hidden state captures the sentence's meaning. A decoder RNN takes that meaning and generates "Le chat s'est assis sur le tapis" in French, one word at a time.
Speech recognition: Audio gets chunked into 20ms segments. An RNN processes each chunk, maintaining context to distinguish "recognize speech" from "wreck a nice beach." This powers Siri and Alexa.
Time series forecasting: Given 60 days of stock prices, an RNN learns patterns and trends in its hidden state, then predicts the next day's price. Similar approaches work for weather forecasting and sensor monitoring.
Why Transformers Replaced RNNs
Despite their success, RNNs have fundamental limitations.
Sequential processing is inherent to their design. You must process sequences step-by-step—you can't parallelize across time. Processing 1000 words requires 1000 sequential operations, making training slow.
Even LSTMs struggle with sequences beyond 200-300 steps. The cell state highway helps but doesn't eliminate long-range dependency problems entirely.
Transformers solve these issues by processing entire sequences in parallel through attention mechanisms. They're 100x faster to train and handle arbitrary-length dependencies without vanishing gradients. This is why GPT, BERT, and ChatGPT all use transformers, not RNNs.
However, RNNs remain useful for real-time applications where data arrives sequentially—live speech recognition, streaming translation, and online time series prediction.
Key Takeaway
Recurrent Neural Networks process sequential data by maintaining hidden state that flows through time. This memory enables context-dependent predictions.
The challenge: vanishing gradients prevent learning long-range dependencies in basic RNNs.
The solution: LSTMs and GRUs use gates to preserve information across 100+ steps, enabling machine translation, speech recognition, and complex time series analysis.
The evolution: Transformers replaced RNNs for most NLP tasks through parallelization and attention, but the fundamental insight—neural networks need memory across time—remains essential.
RNNs introduced temporal memory to deep learning. Transformers scaled it.
Quiz Time
No learning is complete without a knowledge check. Here is a quick quiz to test your knowledge on RNNs. Hope you like this :) Going forward I am planning to include this in every new post.
Quiz link → Quiz on RNN
What's Next
Next week: Attention mechanisms and why they power modern NLP.
Read the full AI Learning series → Learn AI
How was today's email?
