Hey folks,
Over the past two weeks, we covered how neural networks process sequences:
- Issue #43: RNNs - Processing sequences step-by-step through hidden state
- Issue #44: Attention - Focusing on relevant parts through Query-Key-Value matching
This week, we're putting it all together.
Why This Matters to You
When you type something into ChatGPT and get a response in seconds, that's transformers at work. When Google Translate handles a full paragraph almost instantly, that's transformers. When GitHub Copilot autocompletes your code, that's transformers.
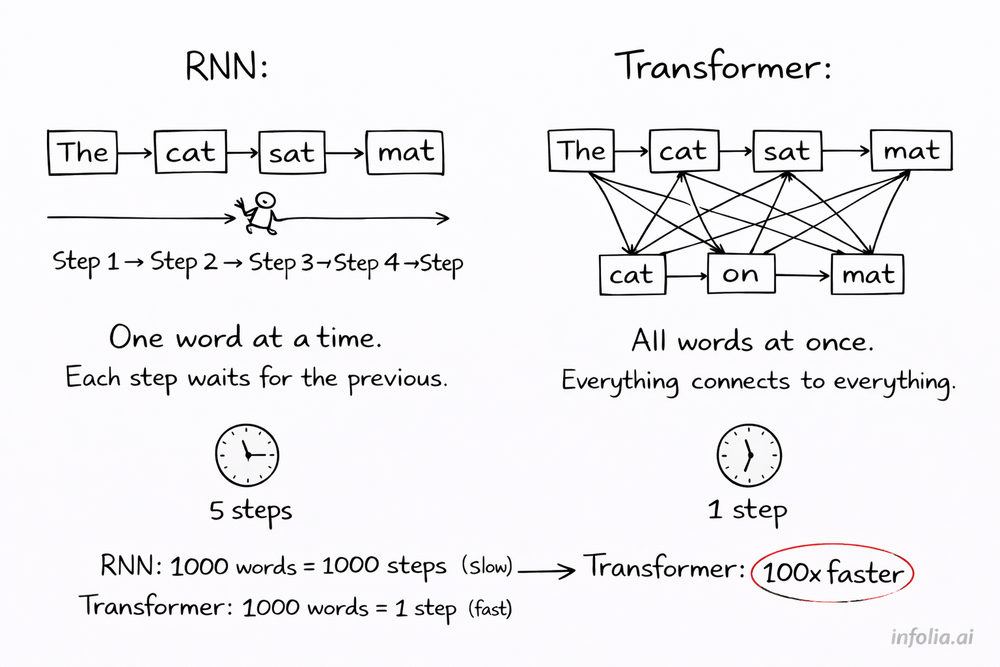
Before 2017, this kind of speed wasn't possible. RNNs processed words one at a time. Slow. Hard to scale. Training large models took forever.
Then a Google research team asked a radical question: "What if we remove RNNs entirely and build everything from attention?"
Their paper was called "Attention Is All You Need." The architecture they introduced - transformers - now powers almost every AI tool you use today.
What Is a Transformer?
Here's a simple way to think about it.
With RNNs, you read a book word by word, trying to remember what came before. With transformers, you see all pages at once and can instantly jump between any two words to understand their relationship.
A transformer is built from repeated layers. Each layer has two main parts:
Multi-head self-attention (from Issue #44) lets each word look at all other words in the sequence and learn relationships between them.
Feed-forward network processes each word's representation independently through a simple neural network.
Stack 12 of these layers, and you get BERT. Stack 96 layers, and you get GPT-3. More layers mean deeper understanding - early layers learn basic syntax, middle layers learn phrases, and deep layers learn meaning and context.
The key difference from RNNs: everything processes in parallel. No waiting for previous words to finish.
The Position Problem

There's a catch with seeing all words at once. How does the network know their order?
To attention, these two sentences look identical:
- "The cat sat on the mat"
- "mat the on sat cat The"
Attention compares words to words. It doesn't care about position. But obviously, word order matters in language.
The fix: Positional encoding.
Before any processing happens, the transformer adds a unique pattern to each word based on its position. Position 1 gets one pattern, position 2 gets a different pattern, position 3 gets another, and so on.
These patterns use sine and cosine functions at different frequencies. Don't worry about the math - the key idea is that each position gets a unique signature that the network can learn from.
The encoding gets added directly to the word embedding:
"cat" embedding: [0.3, 0.5, 0.2, ...]
Position 2 encoding: [0.1, -0.2, 0.4, ...]
Final input: [0.4, 0.3, 0.6, ...]
Now "cat" at position 2 looks different from "cat" at position 5. The network knows word order.
Inside One Transformer Layer
Here's what happens in a single layer:
Step 1: Multi-Head Self-Attention. Each word attends to every other word in the sequence, including itself. With multiple attention heads (usually 8-12), the layer learns different relationship patterns at the same time. One head might focus on subject-verb relationships. Another might learn adjective-noun pairs. Another might track long-range dependencies. All heads run in parallel, then their outputs combine.
Step 2: Add & Normalize. Here's a trick that makes deep networks possible. Instead of just using the attention output, you add it back to the original input (this is called a residual connection). Then normalize the values. This lets gradients flow smoothly during training - without it, networks with 24+ layers would be nearly impossible to train.
Step 3: Feed-Forward Network. Each word goes through the same simple two-layer network independently. No interaction between words here (unlike attention). This adds non-linearity and lets the network transform representations in ways attention alone can't.
Step 4: Add & Normalize again. Another residual connection and normalization. This output becomes the input to the next layer.
That's one complete layer. Stack 12 and you have BERT. Stack 96 and you have GPT-3.
Three Flavors of Transformers
Not all transformers work the same way. There are three main types, and you've probably used all of them today.
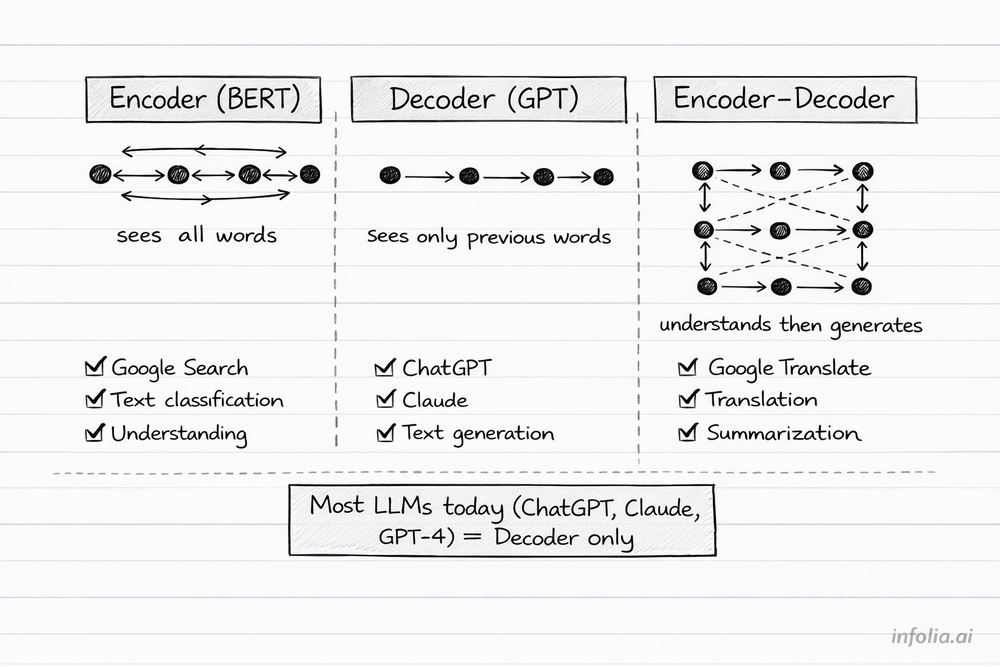
Encoder-only (like BERT) uses bidirectional attention. Each word sees all other words - both before and after it. This is great for understanding text deeply. When you Google something and get relevant results, BERT is helping rank those results by understanding your query and matching it to web pages.
Decoder-only (like GPT) uses causal attention. Each word only sees previous words, never future ones. This is how text generation works - predict the next word based on everything before it. ChatGPT, Claude, GPT-4, Llama - all decoder-only. When you chat with these models, they're predicting one word at a time, but doing it so fast it feels instant.
Encoder-decoder (the original transformer) combines both. The encoder uses bidirectional attention to fully understand the input (like an English sentence). The decoder uses causal attention to generate output (like a French translation) while also attending back to the encoder's understanding. Google Translate works this way.
Most modern LLMs use decoder-only. It's a simpler architecture that scales better.
Why Transformers Won
One word: parallelization.
RNNs process 1,000 words sequentially. Word 1, then word 2, then word 3... all the way to word 1,000. Each step waits for the previous one.
Transformers process all 1,000 words at once. Everything runs in parallel on GPUs, which are built for exactly this kind of computation.
Result: 100x faster training.
This speed enabled scale that wasn't possible before. GPT-3 has 175 billion parameters. It trained on 300 billion tokens of text using thousands of GPUs over several weeks. Total cost: millions of dollars. Only possible because transformers parallelize so well.
And here's the thing about scale - it follows predictable laws. Double the compute, get measurable improvement. This predictability is why we went from GPT-2 (1.5B parameters, 2019) to GPT-3 (175B parameters, 2020) to GPT-4 (2023) so quickly. Researchers could plan these jumps because they knew more scale would work.
Key Takeaway
Transformers replaced RNNs by building everything from attention mechanisms. Positional encoding solves the word order problem. Residual connections make deep networks trainable.
Three types serve different purposes: encoder-only for understanding (BERT powers Google Search), decoder-only for generation (GPT powers ChatGPT), encoder-decoder for translation.
Transformers won because parallelization enables massive scale. And scale unlocks capabilities we didn't expect.
Every major AI breakthrough since 2017 - GPT, BERT, ChatGPT, Claude, DALL-E, Copilot - runs on this architecture.
Quiz Time
Try the Quiz here - https://infolia.ai/quiz/10
What's Next
This completes our deep dive into neural network architectures:
- Issues #34-40: Fundamentals (how networks learn)
- Issue #41: Tensors (data structures)
- Issue #42: CNNs (spatial processing)
- Issue #43: RNNs (sequential processing)
- Issue #44: Attention (dynamic focus)
- Issue #46: Transformers (the complete architecture)
Next week: Embeddings & Vector Spaces
Read the full AI Learning series → Learn AI
How was today's email?
