
You've built something with an LLM. It works, but not quite how you need it to. Maybe it doesn't know about your company's products. Maybe it responds in a generic tone when you need something specific. Maybe it hallucinates when you ask about your internal documentation.
So you search for solutions and find two options everywhere: RAG and fine-tuning.
But which one do you actually need?
Here's the short answer: RAG adds knowledge. Fine-tuning changes behavior. They solve different problems, and picking the wrong one wastes weeks of work.
By the end of this post, you'll know exactly which approach fits your use case — or when you need both.
The One-Line Difference
Think of it this way:
- RAG = Giving the model a cheat sheet at query time
- Fine-tuning = Sending the model to specialized training
Or if you prefer exam analogies: RAG is an open-book test. Fine-tuning is months of studying before a closed-book exam.
Here's the insight most developers miss: fine-tuning doesn't reliably teach facts. It teaches behavior, style, and patterns. If you fine-tune a model on your company documentation hoping it will "remember" that information, you'll be disappointed. The model might learn to sound like your docs, but it won't reliably recall specific details.
This single misconception causes most of the confusion in the "RAG vs fine-tuning" debate.
When to Use RAG
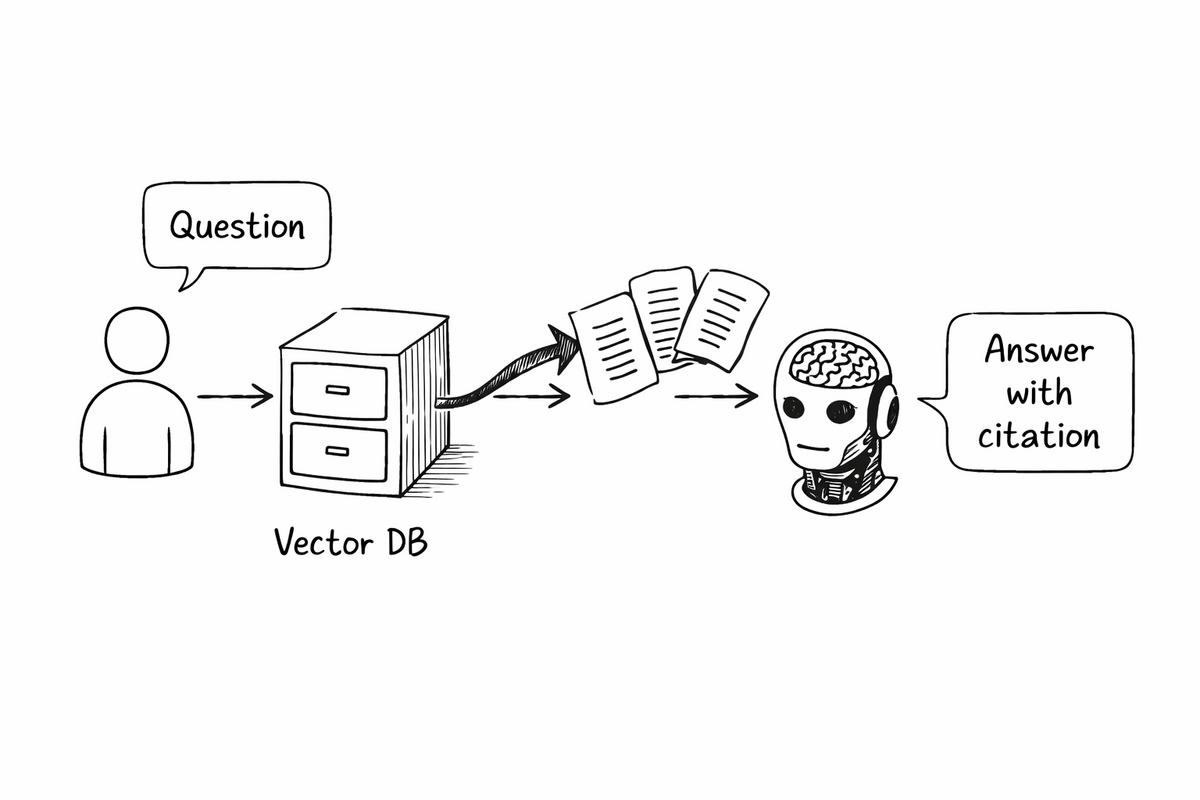
RAG (Retrieval-Augmented Generation) works by fetching relevant information from your knowledge base and injecting it into the prompt before the model generates a response. The model reads this context and answers based on it.
 Use RAG when:
Use RAG when:
- You need the model to answer questions about specific documents, products, or policies
- Your information changes frequently (pricing, inventory, support articles)
- You need to cite sources or show where answers came from
- You're working with private or proprietary data
- You want to get something working in days, not weeks
Real-world example: A customer support bot that answers questions from 500 help articles. When a user asks "How do I reset my password?", the system retrieves the relevant article, adds it to the prompt, and the LLM generates a helpful response based on your actual documentation.
Why RAG works well here:
- Instant updates. Add a new help article, and it's immediately searchable. No retraining.
- Transparent answers. You can show users exactly which document the answer came from.
- Lower hallucination risk. The model is grounded in retrieved content, not guessing from memory.
- Cost-effective. You pay per query (embedding + retrieval + LLM call), but there's no expensive training step.
Most production LLM applications use RAG. It's the pragmatic choice when you need accurate, up-to-date answers from your own data.
Want the technical deep-dive? I break down how RAG actually works — embeddings, vector search, chunking strategies — in my RAG tutorial here.
RAG in the Wild: Apps You Use Every Day
You're probably already using RAG without realizing it. These products feel like magic, but under the hood, they're retrieving information and feeding it to an LLM:
Perplexity AI: When you ask Perplexity a question, it doesn't "know" the answer. It searches the web, retrieves relevant pages, and synthesizes a response with citations. That's RAG. The citations you see? Those are the retrieved sources.
GitHub Copilot: Copilot doesn't have your entire codebase memorized. When you're writing code, it retrieves relevant snippets from your open files, imports, and documentation, then generates suggestions based on that context. Your repo is the knowledge base.
Notion AI: Ask Notion AI about your notes, and it searches your workspace first. It retrieves relevant pages and blocks, then generates an answer grounded in your content. It didn't learn your notes. It looks them up every time.
Cursor IDE: The AI "understands" your project because it indexes your codebase and retrieves relevant files when you ask questions. Delete a file, and it immediately "forgets" it. That's retrieval, not memory.
ChatGPT with browsing: When ChatGPT searches the web, it's doing RAG. It retrieves web pages, extracts relevant content, and uses that as context to generate a response. The "browsing" feature is literally a retrieval system.
Enterprise tools (Glean, Guru, Danswer): These "AI assistants that know your company" work by connecting to Slack, Google Drive, Confluence, and Notion. They retrieve relevant documents per query and let the LLM synthesize answers. No fine-tuning involved.
The pattern is everywhere: retrieve first, then generate. When an AI product feels like it "knows" something specific and current, there's almost always a retrieval system behind it.
When to Use Fine-Tuning
Fine-tuning takes a pre-trained model and trains it further on your specific dataset. This adjusts the model's internal weights, changing how it behaves.
Use fine-tuning when:
- You need a specific tone, voice, or writing style
- The model must follow a precise output format consistently
- You're working with domain-specific jargon or terminology
- You need the model to perform a specialized task (like extracting specific fields from documents)
- Inference speed matters and you can't afford the retrieval latency
Real-world example: A legal tech company needs contracts written in their firm's exact style: specific clause structures, particular phrasing, consistent formatting. Fine-tuning teaches the model these patterns so every output matches the firm's standards.
Why fine-tuning works well here:
- Consistent behavior. The model internalizes the patterns and applies them reliably.
- No retrieval step. Faster inference since there's no database lookup.
- Deep specialization. The model becomes an expert in your specific task.
The big misconception: Many teams think, "I'll fine-tune the model on our company data so it knows everything about us." This usually fails. Fine-tuning is for how the model responds, not what it knows. If you need factual recall of specific information, that's RAG territory.
Fine-tuning is powerful but comes with costs:
- Training requires resources. GPU time, dataset preparation, evaluation cycles.
- Updates mean retraining. Changed your style guide? Time to fine-tune again.
- Risk of "catastrophic forgetting." The model might lose some general capabilities while specializing.
Side-by-Side Comparison
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Best for | Adding knowledge | Changing behavior/style |
| Setup time | Hours to days | Days to weeks |
| Cost model | Per-query (retrieval + LLM) | Upfront training + hosting |
| Updating knowledge | Add docs instantly | Retrain required |
| Hallucination risk | Lower (grounded in docs) | Can still hallucinate outside training |
| Inference latency | Slightly higher (retrieval step) | Faster (no external lookup) |
| Transparency | Can cite sources | Black box |
| Skill required | Standard engineering | ML/fine-tuning expertise |
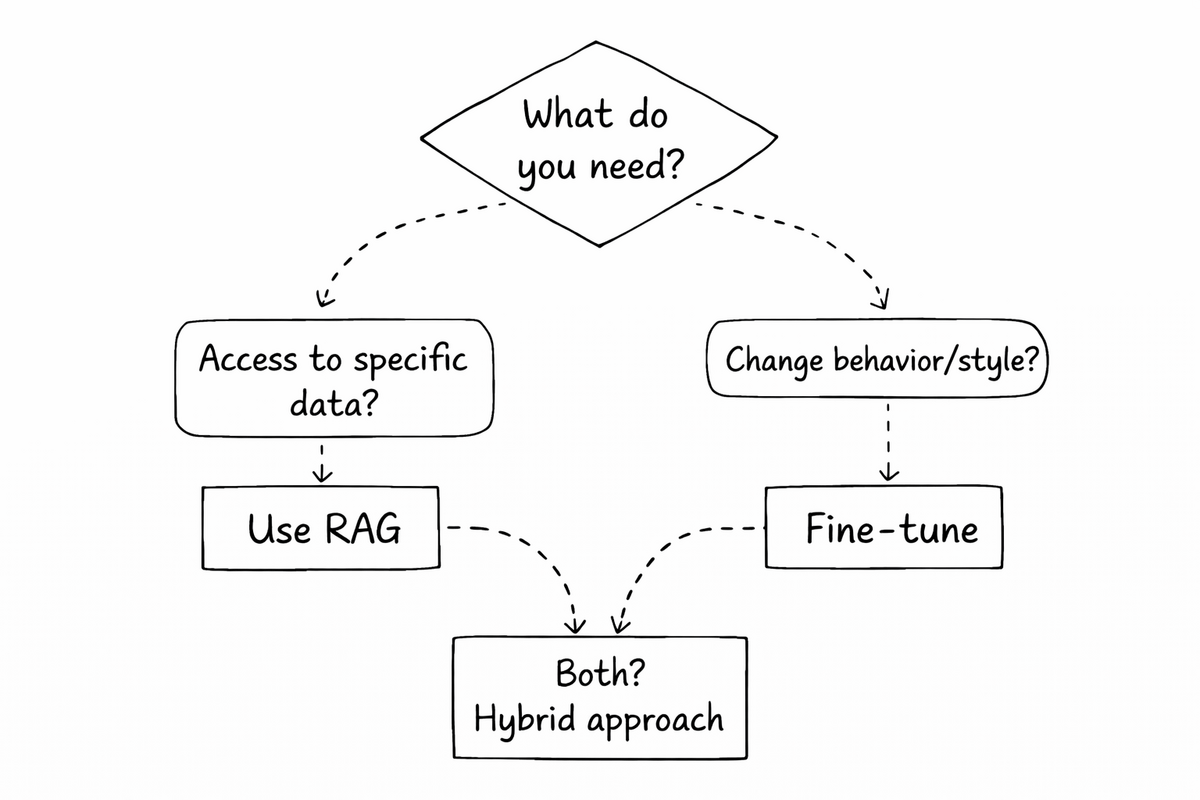
The Decision Framework
Here's a simple flowchart for deciding:
Question 1: Does the model need access to specific, private, or frequently-updated information?
→ Yes: Use RAG
The model needs to "look up" information, not memorize it.
Question 2: Does the model need to behave differently (specific tone, format, or task)?
→ Yes: Use Fine-Tuning
You're changing how the model acts, not what it knows.
Question 3: Both?
→ Use a hybrid approach (more on this below)
When to Use Both: The Hybrid Approach
The most sophisticated production systems combine both approaches:
- Fine-tune for behavior: teach the model your domain's language, your preferred output format, your brand voice
- RAG for knowledge: give it access to current facts, specific documents, real-time data
Example 1: Healthcare Chatbot
Fine-tune on medical literature so the model understands clinical terminology and communicates appropriately with healthcare professionals. Then use RAG to retrieve the latest drug interactions, treatment guidelines, and patient-specific information.
The fine-tuned model knows how to talk about medicine. RAG tells it what to say about this specific query.
Example 2: Legal Document Assistant
Fine-tune on your firm's contract templates so outputs match your exact style and structure. Use RAG to pull relevant clauses from your clause library and reference similar past contracts.
The fine-tuned model writes like your firm. RAG ensures it uses the right content.
This is where enterprise AI is heading. The question isn't "RAG or fine-tuning?" but "how do we combine them effectively?"
Quick Start Recommendations
If you're unsure where to begin:
Start with RAG.
- Lower risk: if it doesn't work, you've lost days, not weeks
- Faster iteration: change your retrieval strategy without retraining
- Easier debugging: you can inspect what was retrieved
- No ML expertise required: standard engineering skills work
Graduate to fine-tuning only when you hit RAG's limits:
- Retrieval quality is good but responses still don't match your needs
- You need consistent output formatting that prompting can't achieve
- Inference latency from retrieval is unacceptable
- You have the ML expertise and resources to do it well
Tools to explore:
For RAG:
- Vector databases: Pinecone, Weaviate, Chroma, pgvector
- Frameworks: LangChain, LlamaIndex
For Fine-tuning:
- OpenAI fine-tuning API
- Together AI
- Hugging Face + your own infrastructure
Common Mistakes to Avoid
Mistake 1: Fine-tuning to teach facts
"We'll fine-tune on our documentation so the model knows our products."
This rarely works. Fine-tuning is unreliable for factual recall. Use RAG for knowledge, fine-tuning for behavior.
Mistake 2: Over-engineering from day one
"We need a fine-tuned model with a custom RAG pipeline and..."
Start simple. A basic RAG setup with a good embedding model and vector database handles most use cases. Add complexity only when you hit specific limitations.
Mistake 3: Ignoring the retrieval step in RAG
RAG is only as good as what it retrieves. If your chunking strategy is poor or your embedding model doesn't capture your domain well, the LLM will generate garbage responses from garbage context. Invest in retrieval quality.
Mistake 4: Treating fine-tuning as a one-time task
Your domain evolves. Style guides change. New patterns emerge. Fine-tuned models need ongoing maintenance and periodic retraining.
Wrapping Up
The RAG vs fine-tuning decision comes down to this:
- RAG = Your data changes, you need citations, you want speed to production
- Fine-tuning = You need specific behavior, consistent style, specialized tasks
- Both = Production-grade systems that need knowledge AND behavior customization
Most developers overestimate their need for fine-tuning. RAG handles 80% of "make the model use my data" problems with less complexity and faster iteration.
Start with RAG. Get it working. Identify where it falls short. Then decide if fine-tuning addresses those specific gaps.
That's the pragmatic path to production.
I write practical AI tutorials for developers every week. If you found this useful, subscribe to the Infolia AI newsletter for more guides like this — no hype, just actionable insights.