Hey folks,
Last week we covered Recurrent Neural Networks - how neural networks process sequences step-by-step through hidden state that carries memory forward through time.
This week: The mechanism that made RNNs obsolete.
RNNs have a fundamental problem: they process sequentially (slow) and struggle to remember information from many steps back. Attention mechanisms solve both by letting the network look at the entire input at once and focus on the most relevant parts.
Let's break it down.
Here's the exciting part: I've added a quiz at the bottom that tests your understanding of this content. Think you can ace it after reading?
The Problem: Too Much Information, Too Small a Container
Imagine summarizing a 50-page document into a single sentence, then trying to answer detailed questions using only that one sentence. You'd lose most of the information.
That's exactly what RNNs do for long sequences.
From Issue #43, you learned:
- RNNs process "The cat sat on the mat" word by word
- Hidden state carries information forward
- But information from early words fades as sequence gets longer
For translation, this creates a bottleneck:
English: "The quick brown fox jumps over the lazy dog near the barn."
The RNN encoder reads all 12 words and compresses them into one hidden state vector (512 numbers). The decoder must generate the entire French translation from just those 512 numbers.
Problem: 12 words of meaning can't fit into 512 numbers without losing details.
What Is a Hidden State Vector? (If You Know Embeddings, You Get It)
If you've worked with vector search or RAG systems, you already understand this concept.
Vector embeddings represent text as arrays of numbers in high-dimensional space:
"neural networks" → [0.23, -0.51, 0.87, ..., 0.42] (768 numbers)
"deep learning" → [0.21, -0.48, 0.79, ..., 0.39] (similar vector - close in space!)
Similar meanings produce similar vectors. That's how vector search finds relevant documents.
Hidden state vectors work identically:
"The cat sat" → [0.34, -0.28, 0.91, ..., 0.15] (512 numbers)
Same concept: compress meaning into a point in multi-dimensional space (512 dimensions instead of 768).
The key difference: Embeddings are static (same input = same output), while hidden states update dynamically as the RNN reads each word.
The bottleneck problem: Compressing a long sentence into one 512-number vector loses information, just like compressing a 50-page document into one embedding would. By word 10 of the translation, the network has forgotten details from word 1.
Attention solves this by keeping separate vectors for ALL words instead of compressing everything into one.
The Insight: What If We Could Look Back?
Instead of cramming everything into one summary, keep the full text available and highlight relevant parts as needed.
Reading analogy:
Bad approach (RNN): Read entire chapter, close the book, write from memory only.
Better approach (Attention): Keep the book open, scan back to relevant paragraphs as you write, focus on what matters for each sentence.
Attention lets the network "keep the book open" - maintain access to the full input while focusing on relevant parts for each output word.
How Attention Works: A Simple Example First
Let's translate "The black cat sat" to French: "Le chat noir assis"
Without attention (RNN way):
- Compress "The black cat sat" into one vector (512 numbers)
- Generate all French words from that same compressed vector
With attention:
- Keep separate vectors for: "The", "black", "cat", "sat"
- When generating "noir" (black): Focus 80% on "black", ignore others
- When generating "chat" (cat): Focus 75% on "cat"
- When generating "assis" (sat): Focus 70% on "sat"
Visualizing as a spotlight:
Generating "noir" (black):
English: The black cat sat
Weights: 5% 80% 10% 5%
↓ ↓ ↓ ↓
Focus: dim BRIGHT dim dim
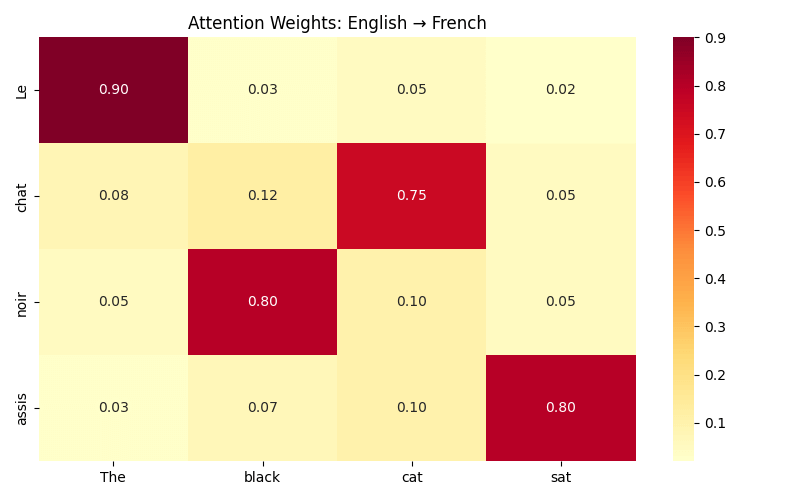
The network learned to focus on "black" when generating "noir," even though French word order differs (chat noir vs black cat). These weights emerge from training data alone.
The Attention Mechanism Explained
Now that you see what attention does, let's understand how it works.
Attention uses three components: Query, Key, and Value.
Library analogy:
You walk into a library looking for books about "neural networks" (your Query - what you're searching for).
Each book has a label on its spine (the Key - what the book is about).
The actual content inside each book is the Value - the information you want if it matches your search.
The process:
- Compare your Query to each book's Key
- Books about neural networks get high match scores
- Books about cooking get low match scores
- Take the high-scoring books and read them (extract their Values)
Query, Key, Value in Neural Networks
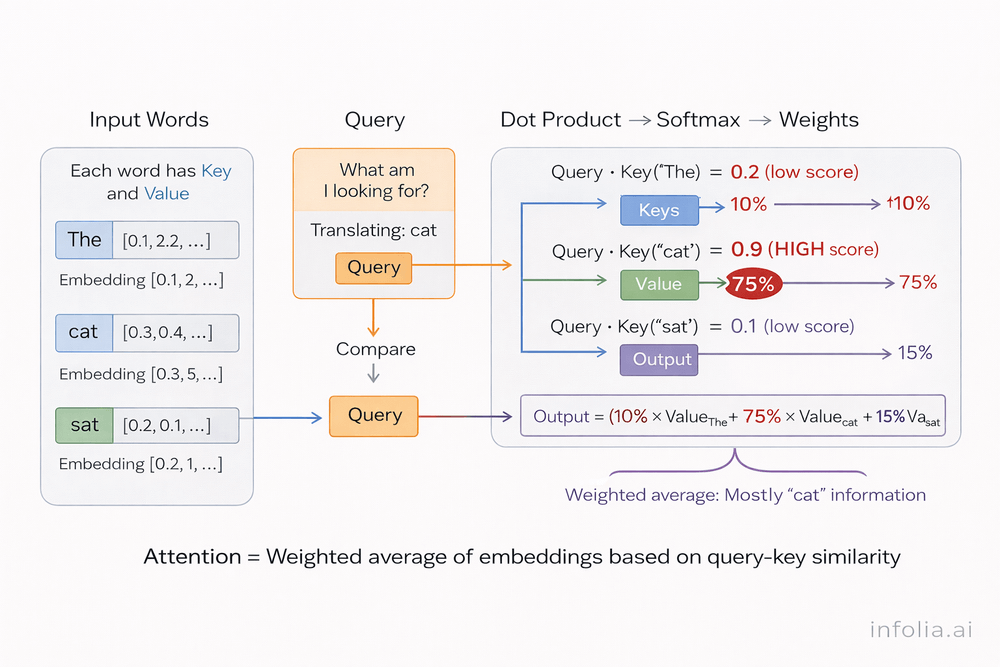
When translating "cat" to French:
Query: "I need to translate the word cat" (from decoder's current state)
Keys: Each English word offers a key
- "The" → Key_1: "I'm an article"
- "cat" → Key_2: "I'm the animal noun"
- "sat" → Key_3: "I'm the action verb"
Values: The actual embeddings from each word
- Value_1: "The" embedding [0.1, 0.2, ...]
- Value_2: "cat" embedding [0.3, 0.5, ...]
- Value_3: "sat" embedding [0.2, 0.4, ...]
Matching:
- Compare Query to all Keys
- Query ("translate cat") matches strongly with Key_2
- Extract mainly Value_2 (cat's embedding with 75% weight)
- Use that to generate "chat"
Think of it as: weighted average of embeddings, where weights come from query-key similarity.
The Math (Simpler Than It Looks)
Step 1: Score each match
Dot product measures similarity:
Score_1 = Query · Key_1 = 0.2
Score_2 = Query · Key_2 = 0.9 ← High! Relevant!
Score_3 = Query · Key_3 = 0.1
Step 2: Convert scores to percentages
Softmax turns scores into weights summing to 1.0:
Weight_1 = 10%
Weight_2 = 75% ← Most attention here
Weight_3 = 15%
Step 3: Get weighted information
Weighted sum of embeddings:
Output = (10% × Value_1) + (75% × Value_2) + (15% × Value_3)
The output heavily contains information from "cat" because it got 75% of the attention weight.
That's it. Query-Key-Value attention in three steps.
Self-Attention: Looking Within the Same Sentence
Attention doesn't need separate input and output sequences. A sentence can attend to itself.
Example: "The animal didn't cross the street because it was too tired."
When processing "it," self-attention shows:
Word: animal street it
Weights: 80% 5% 15%
The network learns "it" refers to "animal," not "street." This coreference resolution emerges automatically from training.
Every word looks at every other word, learning grammatical relationships, semantic similarity, and dependencies.
Why This Is Revolutionary
RNNs: Process word 1 → word 2 → word 3 (sequential). Training 1000 words = 1000 sequential steps. Slow.
Attention: Process all words simultaneously. Word 1's attention computed in parallel with word 2's. Training 1000 words = 1 parallel step. 100x faster.
This speed breakthrough enabled training on massive datasets (billions of words), which enabled modern LLMs.
Multi-Head Attention: Multiple Perspectives
One attention mechanism learns one pattern. Multiple attention heads learn different patterns simultaneously.
Example: Processing "The cat sat"
- Head 1: Syntax (subject-verb relationships)
- Head 2: Semantics (word meanings)
- Head 3: Position (local context)
Each head has separate Query, Key, Value matrices. They operate in parallel, then outputs concatenate. Transformers typically use 8-12 heads per layer, capturing overlapping linguistic patterns.
From Attention to Transformers
In 2017, the paper "Attention Is All You Need" removed RNNs entirely and built everything from stacked attention layers.
The result: Transformers became the foundation of modern AI - BERT (2018), GPT-3 (2020), ChatGPT (2022), and GPT-4 (2023) all use this architecture.
Attention didn't just improve RNNs. It replaced them.
Key Takeaway
Attention mechanisms let neural networks dynamically focus on relevant parts of the input instead of compressing everything into a single fixed-size vector.
The embedding connection: Just like vector search keeps separate embeddings for each document and finds relevant ones, attention keeps separate embeddings for each word and focuses on relevant ones.
The mechanism: Query (what I need), Keys (what's available), Values (the actual embeddings). Compare Query to Keys, get attention weights, extract weighted average of Values.
Self-attention: A sequence attending to itself, learning relationships between words.
The breakthrough: Parallel processing - all attention computations happen simultaneously instead of sequentially, enabling 100x faster training.
The result: Transformers removed RNNs entirely and became the foundation of modern AI.
Next week, we'll see how transformers stack these attention mechanisms into the architecture powering ChatGPT.
Quiz Time
Here is a quick quiz to test your knowledge Quiz link → Quiz on Attention Mechanisms
What's Next
Next week: Transformers and how they power modern language models.
Read the full AI Learning series → Learn AI
How was today's email?
