Last week we covered activation functions, why they're non-linear and why every neuron needs one.
This week: loss functions (also called cost functions). How does a neural network know if its predictions are any good? Loss functions measure that. Let's dive in.
The Problem
Neural networks make predictions all the time.
- Is this a cat or a dog?
- What will the stock price be tomorrow?
- Will this customer buy our product?
But here's the thing: How does the network know if its prediction was any good?
If the network predicts "cat" but it's actually a dog -> that's bad.
If it predicts "cat" and it IS a cat -> that's good.
But you need a mathematical way to measure this "goodness" or "badness." That's what loss functions do.
What Loss Functions Actually Are
A loss function is a mathematical way to measure how wrong your predictions are.
Simple as that.
- The bigger the loss → the worse your prediction
- The smaller the loss → the better your prediction
- The goal: minimize the loss (make it as small as possible)
Think of it like a scorecard.
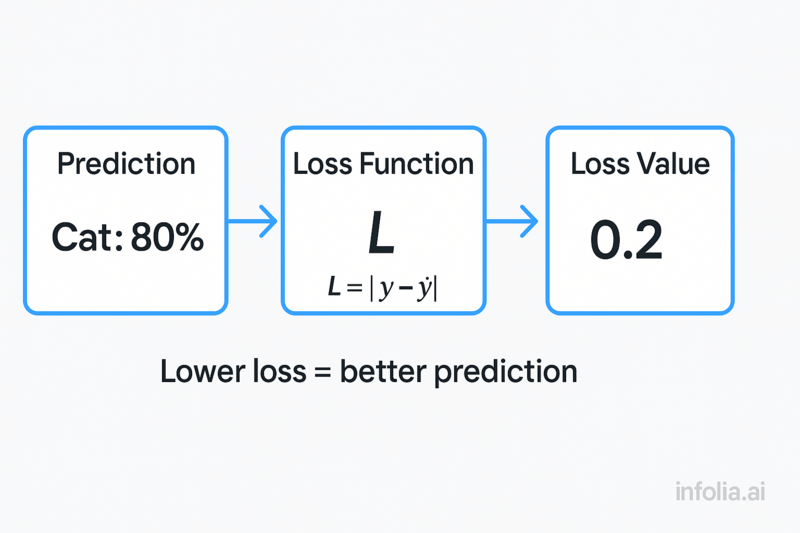
In golf, lower scores are better. In a loss function, lower values mean better predictions.
The network's entire job is to make that loss number as small as possible.
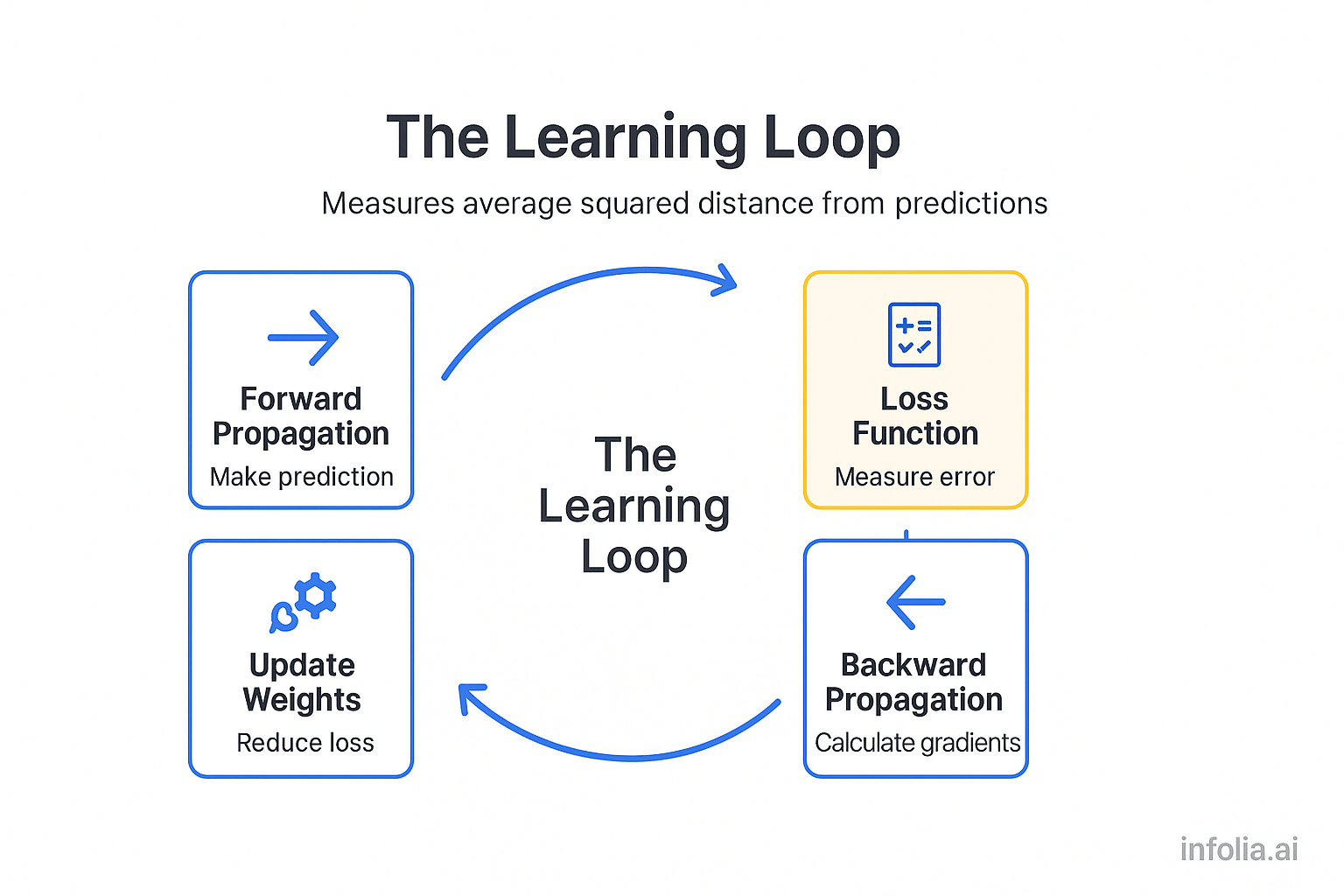
Why We Need Loss Functions
Here's the thing: You can't improve what you don't measure.
Remember backward propagation? It calculates how much each weight contributed to the error, then adjusts those weights to reduce the error.
But backward propagation needs a starting point. It needs to know how much error there is in the first place. That's what the loss function provides.
The flow:
- Forward propagation → makes a prediction
- Loss function → measures how wrong it is
- Backward propagation → uses that measurement to update weights
The loss function is the bridge. It connects "making predictions" to "learning from mistakes."
Without it, the network has no idea if it's improving or getting worse.
The Two Main Loss Functions
There are many loss functions, but two cover 90% of use cases. Below are the two.
1. Mean Squared Error (MSE) - For Regression
What it does: Measures the average squared difference between your predictions and the actual values.
Formula:
MSE = average of (prediction - actual)²
Example: You're predicting house prices.
- Predicted price: $300,000
- Actual price: $320,000
- Error: $20,000
- Squared error: $20,000² = 400,000,000
Do this for all predictions, take the average. That's your MSE.
When to use it:
Use MSE for regression problems -> when you're predicting continuous values.
Examples:
- House prices
- Temperature forecasts
- Stock prices
- Age prediction
Why we square the errors:
Two reasons:
- Makes all errors positive - Without squaring, errors could cancel out (-10 and +10 would sum to 0)
- Penalizes big mistakes more - A $20,000 error is punished way more than a $10,000 error
Visual Example:
Actual: $300k
Prediction: $310k
Error: $10k
Squared: $100M
MSE: $100M (if this is your only prediction)
The bigger the difference, the bigger the penalty.
2. Cross-Entropy Loss - For Classification
What it does:
Measures how far your predicted probabilities are from the actual labels.
Two types:
Binary Cross-Entropy (Two Classes)
For binary classification: cat vs dog, spam vs not spam, yes vs no.
Formula:
BCE = -(actual × log(predicted) + (1-actual) × log(1-predicted))
Don't worry about the math. Here's what matters:
- If you predict 0.9 for "cat" and it IS a cat → small loss (good)
- If you predict 0.1 for "cat" and it IS a cat → big loss (bad)

Example:
You're classifying: Is this a cat?
- Actual: 1 (yes, it's a cat)
- Predicted: 0.8 (80% confident it's a cat)
- Binary Cross-Entropy: ~0.22 (relatively small loss)
Now same image, but you predict:
- Predicted: 0.2 (20% confident it's a cat)
- Binary Cross-Entropy: ~1.61 (much bigger loss)
The more confident you are in the WRONG answer, the bigger your penalty.
Categorical Cross-Entropy (Multiple Classes)
For multi-class classification: cat vs dog vs bird, or digit recognition (0-9).
How it works:
You predict probabilities for each class. The loss penalizes you based on how much probability you put on the correct class.
Example:
Image is actually a "dog."
Your predictions:
- Cat: 0.1 (10%)
- Dog: 0.7 (70%)
- Bird: 0.2 (20%)
You put 70% probability on the correct answer → relatively small loss.
But if you predicted:
- Cat: 0.6 (60%)
- Dog: 0.2 (20%)
- Bird: 0.2 (20%)
You put only 20% on the correct answer → big loss.
When to use it:
Use cross-entropy for classification problems, when you're predicting categories.
Examples:
- Image classification (cat, dog, bird)
- Spam detection (spam or not)
- Sentiment analysis (positive, negative, neutral)
- Disease diagnosis (healthy, sick)
Why Not Use MSE for Classification?
This is a common mistake. "Why can't I just use MSE for everything?"
Short answer: MSE doesn't work well for classification.
Why:
MSE treats all errors equally, it just cares about the numerical distance.
But in classification, you care about probability distributions, not just distances.
Cross-entropy is designed to penalize confident wrong predictions more than MSE does. This leads to better learning.
Example:
Actual: Cat (encoded as 1) Prediction: 0.4
With MSE: Error = (1 - 0.4)² = 0.36 With Cross-Entropy: Error = -log(0.4) ≈ 0.92
Cross-entropy penalizes this more, which helps the network learn faster.
Bottom line: Use the right tool for the job.
How Loss Connects to Everything
Let's tie this back to what we've learned.
The complete picture:
Forward Propagation (Issue #36)
- Input → neurons → activation functions → prediction
Loss Function (this week)
- Compare prediction to actual answer
- Calculate loss (how wrong you are)
Backward Propagation (Issue #36)
- Use the loss to calculate gradients
- Figure out which weights to adjust
Update Weights (next week: gradient descent)
- Adjust weights to reduce the loss
- Repeat until loss is minimized
The loss function is the critical link.
It tells backward propagation how much error there is to work with.
Without it, there's no learning.
Practical Example: Cat vs Dog Classifier
Let's walk through a complete example.
Setup:
- Binary classification: cat (1) or dog (0)
- Using Binary Cross-Entropy loss
Scenario 1: Good Prediction
Image: Cat Network predicts: 0.9 (90% confident it's a cat) Actual: 1 (it IS a cat)
Binary Cross-Entropy: -(1 × log(0.9)) ≈ 0.10
Small loss = good prediction.
The network was confident AND correct.
Scenario 2: Bad Prediction
Image: Cat Network predicts: 0.2 (20% confident it's a cat, 80% dog) Actual: 1 (it IS a cat)
Binary Cross-Entropy: -(1 × log(0.2)) ≈ 1.61
Big loss = bad prediction.
The network was confident in the WRONG answer. Big penalty.
What happens next:
The loss (1.61) gets fed into backward propagation.
Backward prop calculates which weights caused this big error.
Those weights get adjusted more aggressively.
Over time, the loss decreases. The network learns.
Common Mistakes
1. Using MSE for Classification
"I'm classifying cats and dogs, but I used MSE."
Won't work well. Use cross-entropy instead.
2. Using Cross-Entropy for Regression
"I'm predicting house prices using cross-entropy."
Wrong tool. Use MSE for continuous values.
3. Expecting Loss to Reach Zero
"My loss is 0.15, why isn't it 0?"
Loss rarely reaches zero. Perfect predictions are rare. A small, stable loss is the goal.
4. Not Understanding What Loss Means
"My loss is 0.5. Is that good or bad?"
It depends:
- Compare it to your initial loss (is it decreasing?)
- Compare it to a baseline (random guessing)
- For cross-entropy, lower is always better, but "good" depends on the problem
Quick Comparison
| Loss Function | Problem Type | Use Case | Range |
|---|---|---|---|
| MSE | Regression | Continuous values (prices, temperature) | 0 to ∞ |
| Binary Cross-Entropy | Classification | Two classes (cat vs dog) | 0 to ∞ |
| Categorical Cross-Entropy | Classification | Multiple classes (cat vs dog vs bird) | 0 to ∞ |
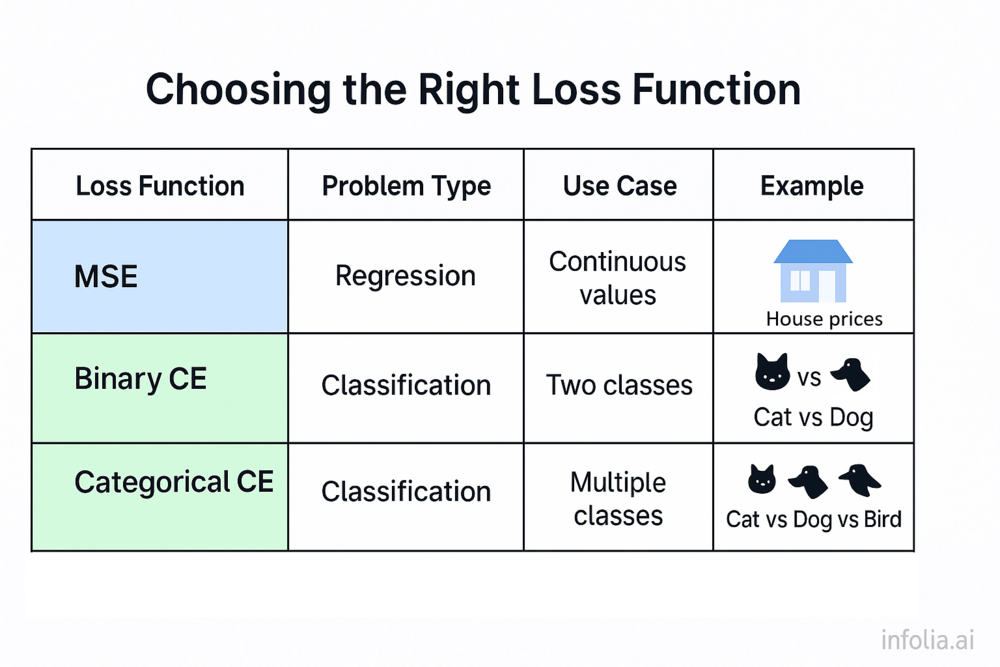
Rule of thumb:
- Predicting numbers? → MSE
- Predicting categories? → Cross-Entropy
Key Takeaway
Loss functions are how neural networks measure their mistakes.
Without them:
- No way to know if predictions are good or bad
- No way for backward propagation to know what to fix
- No learning happens
With them:
- Network knows how wrong it is
- Backward propagation knows which weights to adjust
- Learning becomes possible
The two you need to know:
- MSE for regression (predicting continuous values)
- Cross-Entropy for classification (predicting categories)
Think of the loss function as the network's report card.
Lower loss = better grade = network is learning.
Next Week
Now you know how to measure mistakes. But how do we USE that measurement to actually improve? We know the loss. We know which weights contributed to it (thanks to backward propagation). But how do we update those weights to reduce the loss? That's where gradient descent comes in.
Next week, we dive into gradient descent optimization algorithm that makes all of this learning actually work.
Read the full AI Learning series:
-
- Loss Functions ← You are here
Anthropic Acquires Bun & Claude Code Hits $1B in 6 Months
The AI coding war just got real.
Anthropic made its first acquisition on December 2nd: Bun, the JavaScript runtime that's 3x faster than Node.js.
The number that matters: Claude Code reached $1 billion in run-rate revenue just six months after going public.
Bun is a complete JavaScript toolkit - runtime, package manager, bundler, and test runner in one blazing-fast executable. Downloads grew 25% last month, hitting 7.2 million monthly.
The catch? There isn't one. Bun stays 100% open-source and MIT-licensed. Same team, same roadmap, built in public on GitHub.
What this means: Claude Code ships as a Bun executable to millions of users. Anthropic has direct incentive to keep it excellent.
DeepSeek is giving away GPT-5-level models. Anthropic is printing $1B with Claude Code. OpenAI declared "Code Red."
The AI coding wars are heating up.
Google's Gemini 2.5 Pro Takes #1 on Coding Leaderboards
Google just caught up.
Released March 25th, Gemini 2.5 Pro hit #1 on LMArena by a significant margin. But here's what matters for developers: it's a thinking model built specifically for coding.
Chain-of-thought reasoning is baked into the model, not a prompt hack. It reasons through its thoughts before responding, delivering better accuracy on complex multi-step problems.
The wins: #1 on WebDev Arena for building functional web apps. Powers Cursor's code agent. Cognition calls it the first model to solve their "larger refactor" eval.
The killer feature: 84.8% on video understanding. Paste a YouTube link and it generates a fully interactive learning app, complete UI, not just code snippets.
The specs: 1 million token context window, native multimodality, adaptive thinking. Available now in Google AI Studio.
Bottom line: You now have three frontier coding models. The developer experience just got competitive.
How was today's email?
